Fast Wildcard Matching in C Sharp


Recently I have been working on a .u3d (ECMA 363 4th Edition) compliant decoder in c#. In the specification for the External File Reference block is the requirement to support file name filters that may have the wildcard characters ‘?’ and ‘*’. Dot Net does not include a native method for matching wildcards characters in strings, so I went online to see what solutions others have come up with.
Turns out a really popular response to matching wildcards is to use RegEx. Unless the application is just doing this check once and never again, I cannot communicate just how poor this solution is. It is by far the simplest; a couple lines of code and you are done. RegEx is very powerful but that power comes at a cost; I had to remove it from the full test as it was just too time consuming. Recursive algorithms also seem to be a popular choice, but again they can be slow. I tried the Visual Basic “trick” and even though the performance was more suitable it failed on many of the test cases. The test consists of 100 different strings and wildcard strings that I gathered from the web. Some are “gotchas” intended to test if the method meets the requirements of wildcard rules others are possible uses like URLs. I did eventually find a method that only fails on one test case. I still felt this method was too slow for use in a file loader/decoder. So I decided to throw my hat into the ring and see if there was any way, ugly or elegant that would be faster and still pass every test. I am accustomed to writing real time code that must perform its duty fast enough that the application can go through a full update in 16-33 milliseconds (60 – 30 frames per second). I was determined even if it had to be some sort of dirty hack.
When writing high performance / real time code you often have to find some behavior or property that you can exploit. So I did what I often will do and manually wrote out test cases on a yellow note pad and stepped through the problem over and over again. Developing the algorithm in my mind and exploring different approaches; always keeping an eye out for something inherent about the problem that can be exploited for greater efficiency.
The basic rules are very simple, that is until you have to match the ‘*’ wildcard. The good news is that it is not a wildcard, at least not in its behavior. I noticed that it behaved like a 1D Vector(you can call it an offset if you prefer). It has a direction and a magnitude, we know the direction but not the magnitude. Since this is a 1D problem and we know the direction of this mystery vector we can find out its length is a straightforward way. We search for its end going by tracing backwards. The problem is that ‘*’ can contain nothing or everything, every possible pattern, including duplicates of the pattern that it precedes. To find the end you would have to search all the way to the end of the string until you found the last instance of the pattern that follows it. Recursion comes in real handy for a problem like this. But we can code something faster if we just re-frame the problem to reflect its behavior.

Exploitable Observations of Wildcard Behavior
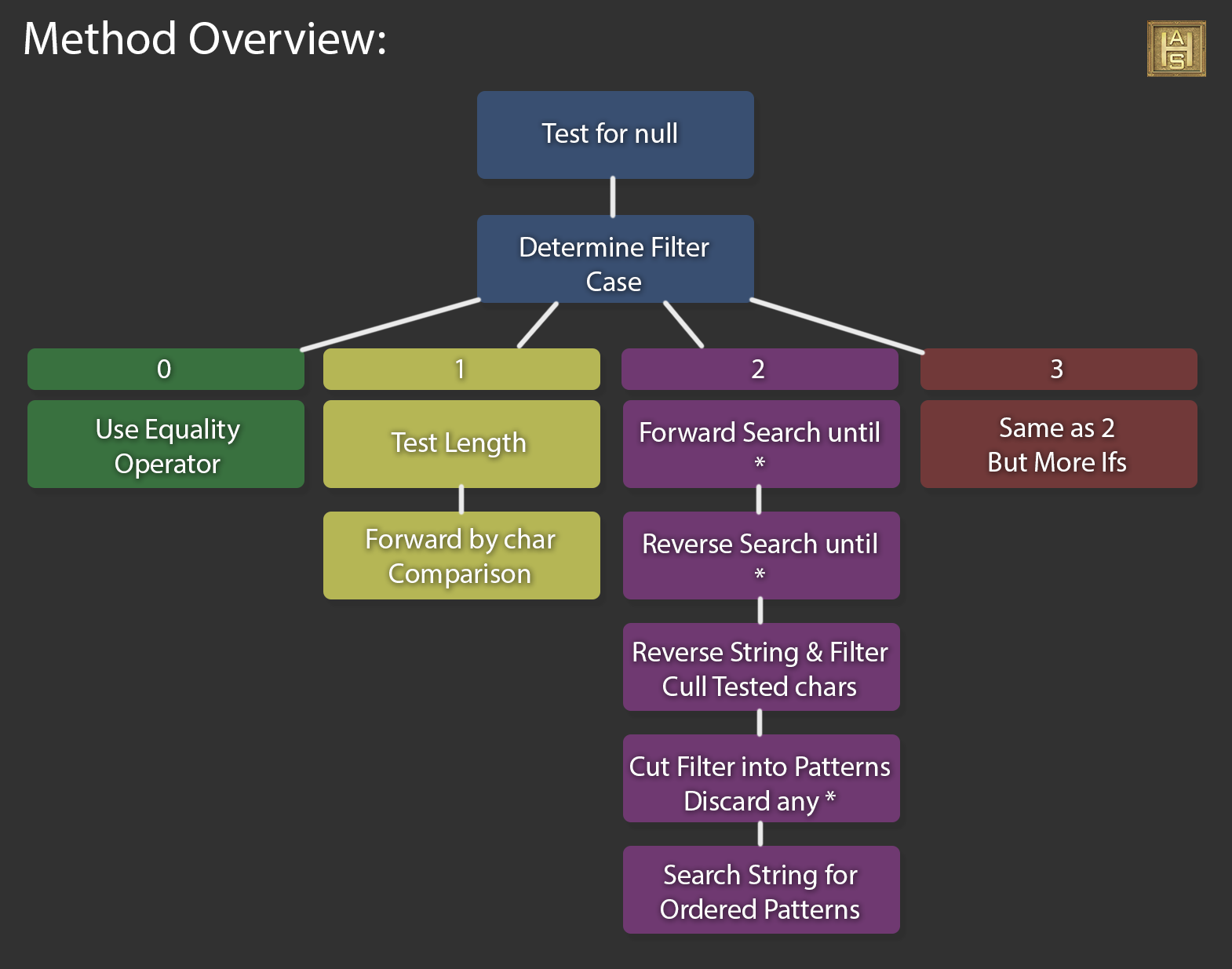
After re-framing the problem to better reflect its behavior and not its descriptions, I was able to make some very exploitable observations. A filter can be of 4 possible cases of increasing complexity that we can use to specialize the technique and squeeze out extra performance (on average). For no wildcards we can just use the normal equality test. If it has only ‘?’ wildcard we can “early out” on a length check, or step through each char. If it contains only the ‘*’ wild card we can remove those extra if statements (remember, the goal is as fast as possible even if some think its ugly). If it has both the ‘?’ and ‘*’ wildcards then we go all in. (Its just an if, but it does get called for every comparison. My tests showed it was a bit faster on average to split the cases.)
If the filter does not start with an ‘*’ then we can do a lightweight linear search for mismatches and fail early. The same goes if the filter does not end with an ‘*’. If he head and tail are not an ‘*’ we can assume the pattern is anchored to its respective end. The method mainly concerns itself with searching for a set of patterns in order. It does not try to find a match, it tries to find a mismatch to fail out as quickly as possible. Any set of characters (including ?) between ‘*’s are treated as patterns. As such, we can cut them up at the ‘*’ boundary and reduce the number of comparisons made to find a mismatch. Finally the ‘*’ character is a vector and all we need to do is find its end. This can be done very easy by searching through the string in reverse. When searching backwards we know that the first match to an ordered pattern is the last match when going forwards. We can update an variable to the last passed index and not touch those characters again. This reduces the number of comparisons considerably.
Wildcard Matching Method Overview
I will focus in on Case 2 for an overview of the algorithm as the rest is straight forward.
Since comparing patterns char by char is expensive, I try to do as much cheap stuff upfront as possible. The first step is to do a forward char by char comparison until an ‘*’ is encountered. Then do this again in reverse from the end of the filter and string. By starting this way we can look for any mismatches pretty fast. If there are no mismatches, the filter and string are reversed, discarding any of the characters that were previously tested. The filter is then cut up into patterns and any ‘*’ are discarded, as this method does not require them past marking non-anchored patterns. The final step is to loop through each pattern in order and match it up to the string. This works well as each char is only compared a minimal number of times. Reducing the work needed to be done.
Performance comparisons were performed between this method and 3 other popular methods. RegEx had to be dropped out early as it would take too much time to complete the test. In Defense of RegEx it was the only other method not to fail at least one of the filters in the test set. The Visual Basic “trick”, while quick, failed way too much on the test set to be considered. The next popular method performed well and only failed one test case. The method presented to you in this article passed all test cases and averaged 2275 ms for 10,000,000 comparisons (100 test cases at 100,000 reps). This is about 7 times faster than the other popular method tested.
The source code can be found here and the source with test set can be found here if you are interested in comparing it to your preferred method or contributing to its improvement.
H.A. Sullivan
Comments are Disabled